LiteLLM is the central control layer behind your AI infrastructure. Set budgets, track usage, manage access – entirely on your own hardware, no cloud, no data sharing.
LiteLLM is an open-source API gateway for language models. It sits as an invisible layer between your employees and the AI models running in the background – giving you complete control over who may use what, for how long, and at what cost.
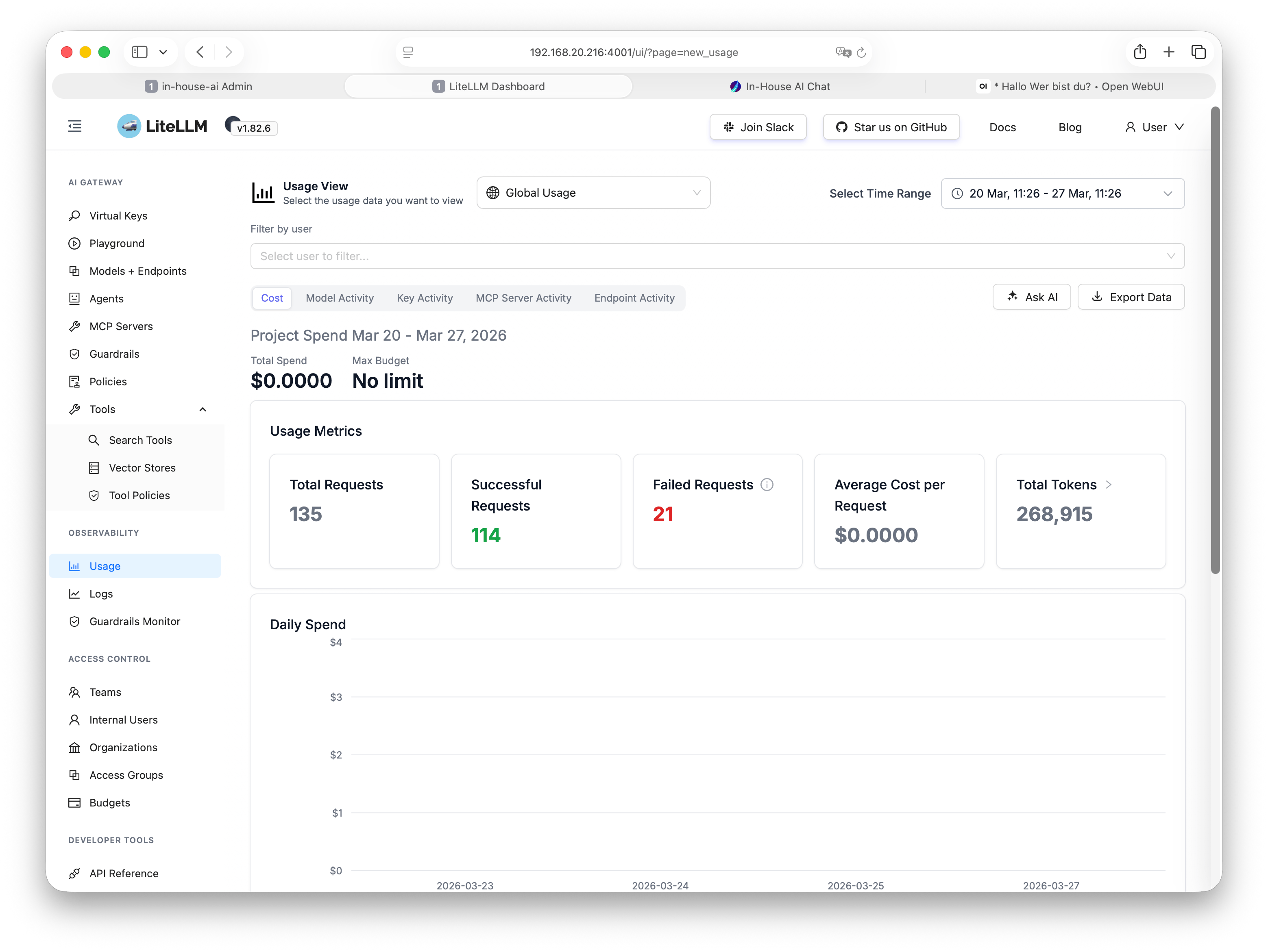
In practice, this means department heads can see exactly which teams are using which models and how intensively. IT administrators can set budgets per team, project, or user. And management gets an on-demand overview of AI usage across the entire organization.
Everything stays on your own hardware. Not a single request leaves your network. LiteLLM logs internally and stores no data with third parties.
LiteLLM is the backbone of your AI infrastructure.
While Open WebUI or LibreChat provide the interface for your
employees, LiteLLM handles the control layer behind the scenes:
which model is called? Is the budget still available?
Who has made the most requests this week?
For organizations with multiple teams or departments, this level
of transparency and control is indispensable.
LiteLLM is more than a proxy. It is the control centre for all AI activity in your organization.
Set monthly or weekly limits per user, team, or department – with automatic lockout when the limit is reached.
Every request is logged: timestamp, model, token consumption, user. Full transparency with zero extra effort.
Issue API keys per user or application. Each key can be restricted to specific models or budgets.
Automatically route requests to the most suitable model – based on task type, load, or availability.
Access all models through a single OpenAI-compatible interface – regardless of whether Llama, Mistral, or Qwen is running underneath.
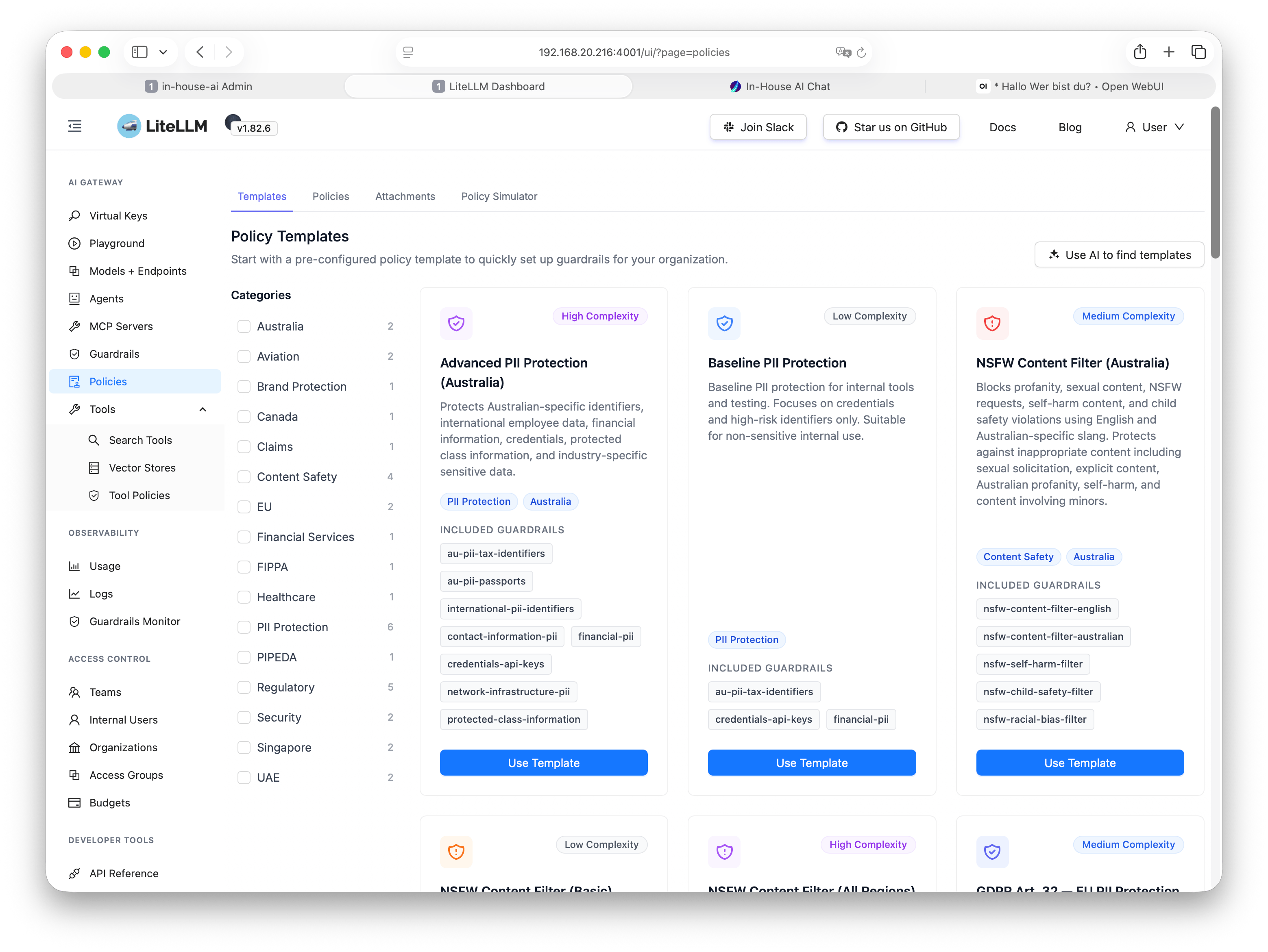
Define and enforce usage policies for models, content, and request volumes centrally – no per-user configuration required.
A clear admin panel for all settings – usage, budgets, keys, and logs at a glance, directly in the browser.
All logs, statistics, and keys remain on your hardware. No third-country transfers, no external dependencies.
Automatically switch to an alternative when a model fails. Distribute requests across multiple instances.
LiteLLM is part of our complete AI stack – we set up everything together on your hardware.
We install LiteLLM on your existing or newly supplied hardware – as a container that starts and runs automatically.
All running language models are registered in LiteLLM and assigned sensible routing rules – tailored to your use cases.
We create departments, budget limits, and API keys – aligned with your organizational structure, not a rigid template.
You receive access to the admin dashboard and a brief walkthrough. From that point on you have full control – and we are available for any questions.
We always deploy LiteLLM together with the appropriate chat interfaces and LLM runners. The result is a complete, production-ready AI stack for your organization – from a single source, on your hardware.
Typical combination: Open WebUI or LibreChat as the chat interface for employees, LiteLLM as the gateway in the background, Ollama as the LLM runner for the models. Everything set up, tested, and handed over together.
No vendor lock-in, no subscriptions, no monthly licence fees. Once deployed, the system belongs to you.
We show you how LiteLLM, Open WebUI, and your models work together – in a personal demo, free and non-binding.