Live-Einblick
Das LiteLLM Admin-Panel in der Praxis
Nutzungsübersicht und Richtlinienverwaltung – alles in einem übersichtlichen Web-Dashboard, direkt im Browser.
 Vergrößern
Vergrößern
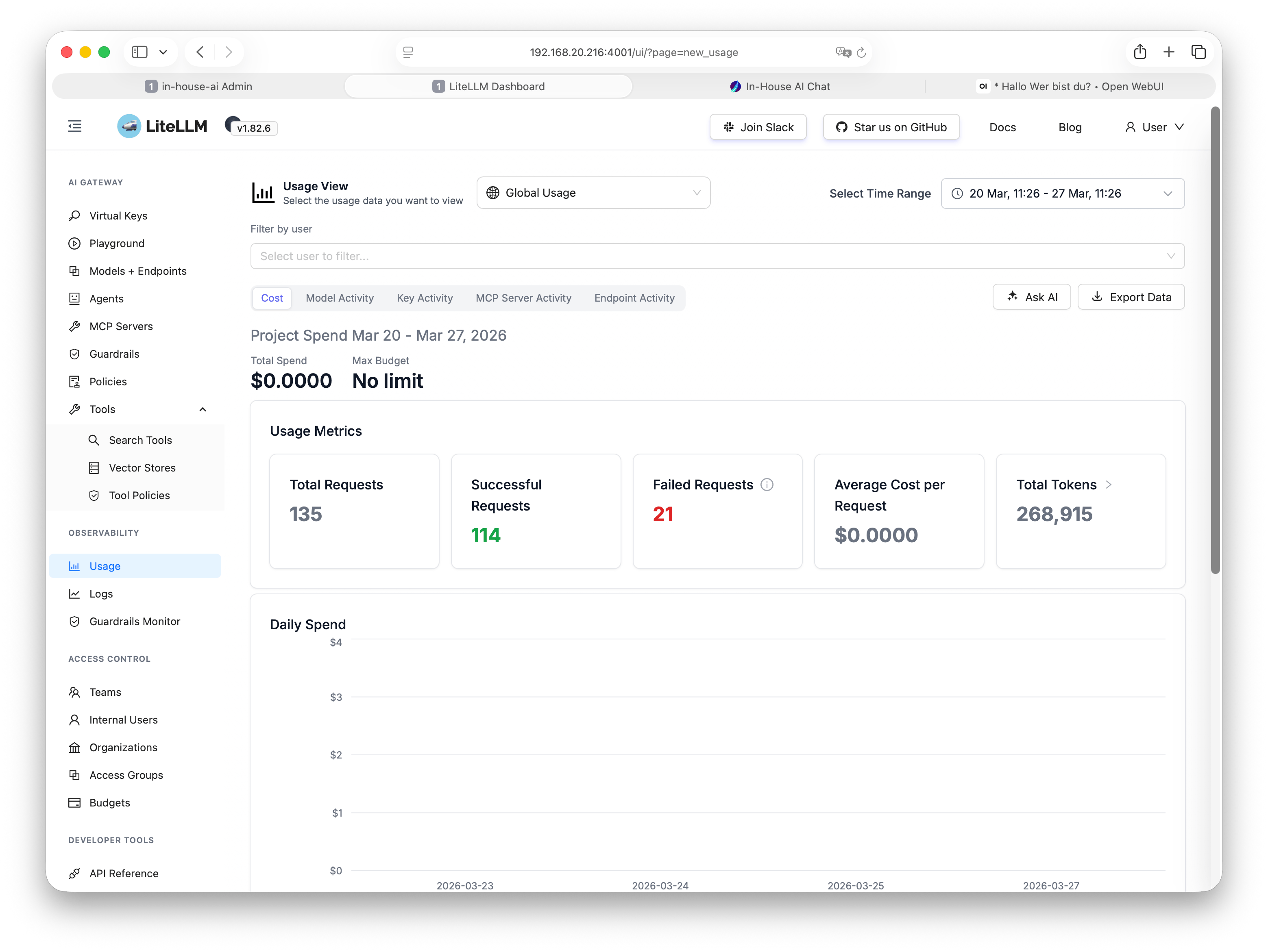
Nutzungsübersicht & Token-Verbrauch
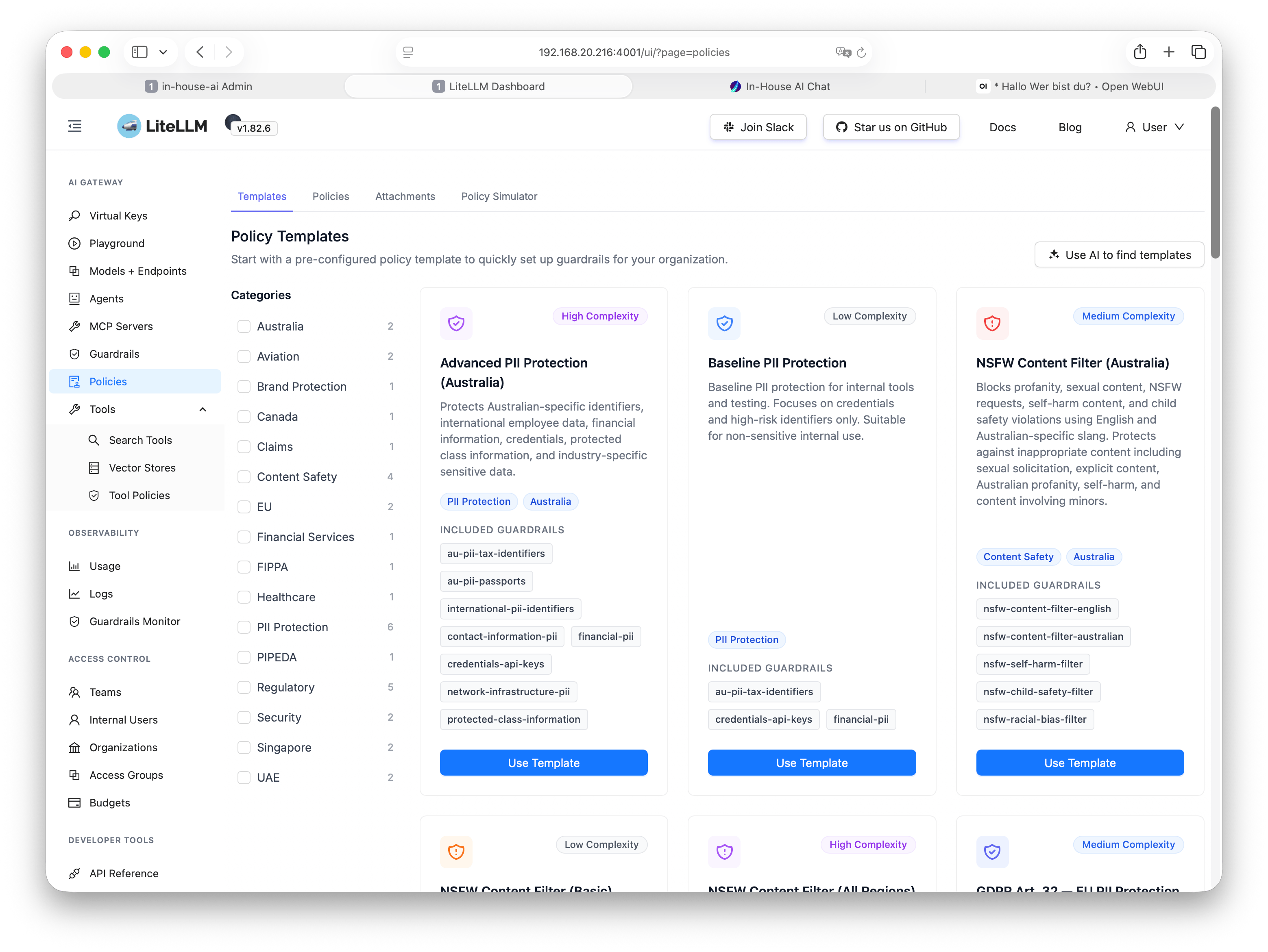 Vergrößern
Vergrößern
Policies & Zugriffsregeln